Main API offline
Incident
Report for Jestor
Postmortem
The root cause of the problem is database storage. Autoscaling has failed to occur at an appropriate time, which has caused issues while the application connects to the database.
To prevent this to occur in the future, we have implemented a very aggressive autoscaling policy, and more efficient alarms to prevent those kinds of situations.
The downtime was about 25 minutes long, between 11h40AM UTC and 12h05 UTC
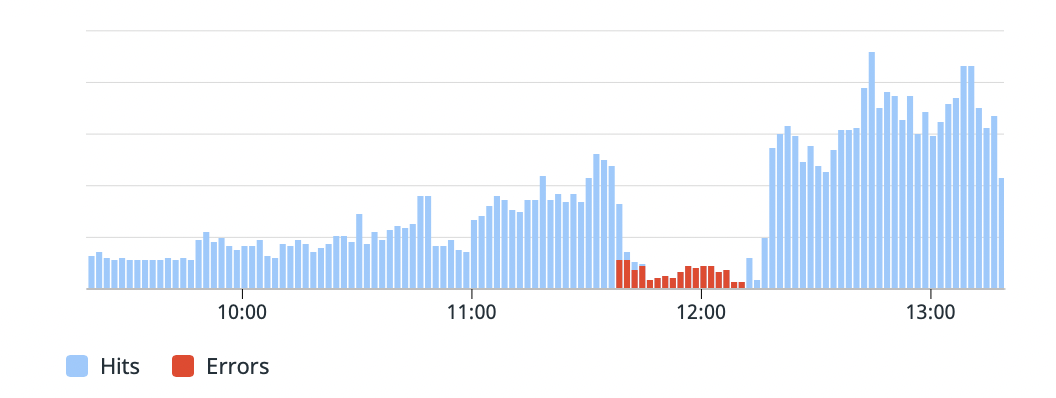
Resolved
Everything is fine!
Update
Everything seems fine right now. We are continuing to monitor to avoid any other related issues occurring.
Update
We are continuing to monitor the change and response time.
Monitoring
It has started to back to work. Still slow to load some resources due to CPU usage in our DB (the CPU is high due to applied changes)
Identified
Our main API is down due to an issue with the database. We have identified the issue and we are working on it right now. Expected time to solve: 10 minutes
This incident affected: API and Account creation.